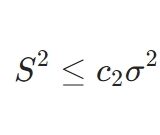どうも、木村(@kimu3_slime)です。
今回は、統計的仮説検定とは:平均の検定、t検定を例に、Juliaを使って紹介します。
統計的仮説検定とは
統計的仮説検定(statistical hypothesis test)は、統計的推論の一種で、統計モデルに関して立てる仮説が正しいかどうか、データにもとづき確率的に判断することです。単に検定とも。
典型的な仮説としては、「平均の値が50である」などパラメータに関するものがあります。
平均の検定、t検定
平均に関する検定を行ってみましょう。
正規分布に従う乱数を使い、次のような10個のデータが得られたとします。ただし、指定した平均や分散は知らないものとしましょう。
1 2 3 4 | using HypothesisTests, Distributions, Random d1 = Normal(50,10) Random.seed!(2022) x = rand(d1,10) |
1 2 3 4 5 6 7 8 9 10 11 | 10-element Vector{Float64}: 50.6912301164913 38.84399961848597 42.84480604223728 60.9769650429804 54.978651946367876 33.951339022096505 40.96806064167559 32.42960541746047 49.11909337153176 48.368593011534614 |
このデータの平均を計算すると、
1 | mean(x) |
1 | 45.31723442308618 |
です。
このデータが正規分布に従っていると仮定するとき、母集団分布の平均\(\mu\)が\(\mu =45\)であるという仮説が正しいかどうか、調べてみましょう。調べたい仮説
\[H_0 : \mu =45\]
は、帰無仮説(null hypothesis)と呼ばれます。これに対し、それが否定されるときの仮説
\[H_1: \mu \neq 45\]
は、(両側)対立仮説(alternative hypothesis)と呼ばれます。
パラメータが特定の値であるという仮説は、\(\mu=40,41,42,\dots\)のように無数にあります。すべて同時に比較するのはキリがありません。
そこで、帰無仮説とそれに対立する仮説を設定し、2つの仮説の確率的な比較を行うわけです。
正規分布からランダムサンプリングして得られた\(n\)個のデータについては、統計量
\[T= \frac{M_n -\mu}{\frac{S}{\sqrt{n}}}\]
が自由度\(n-1\)のt分布に従うことが知られています。帰無仮説の\(\mu =45\)とデータ、t分布を用いれば、区間推定と同様に確率が計算できます。
t分布を使った検定はt検定(t-test)、統計量\(T\)はt検定量(t-statistic)と呼ばれるものです。検定に用いる統計量は、一般に検定統計量(test statistic)と呼ばれます。
仮説の検討にあたり、有意水準(significance level)と呼ばれる数値\(\alpha\)を決めましょう。これは信頼区間における信頼水準\(\gamma\)に対応するもので、偶然による違いをどこまで許容するかを示します。
小さな値として、\(\alpha=0.05, 0.01,0.001\)などが選ばれることが慣習的に多いです。今回は、\(\alpha = 0.05\)として考えてみましょう。
t分布を使えば、
\[P(-c \leq T \leq c) = 1- \alpha\]
となる\(c\)を求めることができます。これを整理し、具体的な値を当てはめると、
\[P(45- c \frac{S}{\sqrt{n}} \leq M_n \leq 45 +c \frac{S}{\sqrt{n}}) =0.95\]
となりました。
もしサンプル平均\(M_n\)がこの範囲に入るならば、帰無仮説は棄却しません(fail to reject)(採択(accept)されるとも言う)。そうでないならば、帰無仮説を棄却(reject)し、対立仮説を採択します。これが的検定の考え方です。
サンプルにもとづき帰無仮説が棄却されるような範囲は、棄却域(rejection region, critical region)と呼ばれています。
パラメータに関する検定の流れをまとめると、次のようになります。
- 統計モデルを仮定する。
- 帰無仮説\(H_0\)と対立仮説\(H_1\)を決める。
- 有意水準\(\alpha\)を決める。
- 統計モデルと仮説にもとづき、仮説が正しいとき、サンプル\(X_1,\dots,X_n\)が得られる確率と範囲を求める。
- 観測したサンプル\(x_1,\dots,x_n\)を用いて、検定統計量を計算する。
- 4で求めた確率にもとづき、仮説を棄却しないか、棄却するか判断する。
Juliaでt検定を行う
Juliaでは、HypothesisTestsというパッケージで、統計的仮説検定ができます。
帰無仮説\(\mu = \mu_0\)を検証するt検定は、「OneSampleTTest(データ, \(\mu_0\))」です。
1 | test1 = OneSampleTTest(x, 45) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 45 point estimate: 45.3172 95% confidence interval: (38.77, 51.86) Test summary: outcome with 95% confidence: fail to reject h_0 two-sided p-value: 0.9151 Details: number of observations: 10 t-statistic: 0.10964349244351655 degrees of freedom: 9 empirical standard error: 2.8933265077232178 |
95%信頼水準(5%優位性水準)においては、\(H_0\)を棄却できません(fail to reject)。つまり、\(\mu =45\)でありうるということですね。
計算されているp値(p-value)とは、このデータを使って帰無仮説が棄却されるような有意水準のうち、最小の値\(\alpha_0\)のことです。言い換えれば、p値が検定に用いる有意水準\(\alpha\)より低いならば、帰無仮説は棄却されます。
今回は、p値は約0.9です。\(\alpha =0.05\)での検定はおろか、\(\alpha=0.8\)ですら\(\mu =45\)は棄却されません。
さまざまなパラメータの値に関する仮説を検証してみましょう。
1 2 3 | for θ in 30:10:60 display(OneSampleTTest(x, θ)) end |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 30 point estimate: 45.3172 95% confidence interval: (38.77, 51.86) Test summary: outcome with 95% confidence: reject h_0 two-sided p-value: 0.0005 Details: number of observations: 10 t-statistic: 5.293987519970373 degrees of freedom: 9 empirical standard error: 2.8933265077232178 One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 40 point estimate: 45.3172 95% confidence interval: (38.77, 51.86) Test summary: outcome with 95% confidence: fail to reject h_0 two-sided p-value: 0.0993 Details: number of observations: 10 t-statistic: 1.837758168285802 degrees of freedom: 9 empirical standard error: 2.8933265077232178 One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 50 point estimate: 45.3172 95% confidence interval: (38.77, 51.86) Test summary: outcome with 95% confidence: fail to reject h_0 two-sided p-value: 0.1400 Details: number of observations: 10 t-statistic: -1.6184711833987688 degrees of freedom: 9 empirical standard error: 2.8933265077232178 One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 60 point estimate: 45.3172 95% confidence interval: (38.77, 51.86) Test summary: outcome with 95% confidence: reject h_0 two-sided p-value: 0.0007 Details: number of observations: 10 t-statistic: -5.074700535083339 degrees of freedom: 9 empirical standard error: 2.8933265077232178 |
\(\mu = 30, 60\)という仮説は、棄却されました。\(\mu =40,50\)という仮説は、棄却されませんでしたね。
仮説や信頼水準が同じでも、サンプル数を変えると検定の結果は変わりえます。
帰無仮説が\(\mu =45\)、\(\alpha= 0.05\)で、同じサンプルについてサンプルサイズを大きくしていきましょう。
1 2 3 4 5 | for n in 10:10:30 Random.seed!(2022) x = rand(d1,n) display(OneSampleTTest(x, 45)) end |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 45 point estimate: 45.3172 95% confidence interval: (38.77, 51.86) Test summary: outcome with 95% confidence: fail to reject h_0 two-sided p-value: 0.9151 Details: number of observations: 10 t-statistic: 0.10964349244351655 degrees of freedom: 9 empirical standard error: 2.8933265077232178 One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 45 point estimate: 46.3116 95% confidence interval: (40.95, 51.68) Test summary: outcome with 95% confidence: fail to reject h_0 two-sided p-value: 0.6147 Details: number of observations: 20 t-statistic: 0.5118012579919081 degrees of freedom: 19 empirical standard error: 2.5626800736911317 One sample t-test ----------------- Population details: parameter of interest: Mean value under h_0: 45 point estimate: 49.3313 95% confidence interval: (45.18, 53.49) Test summary: outcome with 95% confidence: reject h_0 two-sided p-value: 0.0416 Details: number of observations: 30 t-statistic: 2.1318149144048357 degrees of freedom: 29 empirical standard error: 2.031762320944905 |
サンプル数20までは帰無仮説は棄却されませんが、サンプル数30の時点では棄却されます。つまり、\(\mu \neq 45\)と考えられるわけですね(実際これは正しい)。
ただし、サンプル数30のとき、p値は0.04なので、もし有意性水準を\(\alpha =0.01\)としていたならば、まだ\(\mu = 45\)は棄却されません。同じデータを用いていても、有意性水準の設定の仕方によって、帰無仮説が棄却されるかどうかが変わることに注意しましょう。
統計的仮説検定の注意点
検定における採択・棄却は、確率的な判断であることに注意しましょう。
「100%正しい・間違っている」という証明のようなものではなく、確率的な推論であることによる限界があります。
帰無仮説のほうが正しいにもかかわらず、5%(有意水準\(\alpha\))の確率で、サンプル平均が
\[P(45- c \frac{S}{\sqrt{n}} \leq M_n \leq 45 +c \frac{S}{\sqrt{n}}) =0.95\]
という範囲に入らず、対立仮説が採択されることがありえます。これは第一種の過誤(type I error)と呼ばれています。
これと逆に、対立仮説が正しいけれども、検定によって帰無仮説が採択されることはありえて、それは第二種の過誤(type II error)と呼ばれています。
また、仮説を採択・棄却するという言葉の受け止め方にも注意が必要です。仮説が採択されるということは、それが「唯一正しい仮説である」ことや「最も望ましい仮説である」ことを意味しません。「棄却はできない」程度の意味です。\(\mu =45\)の帰無仮説も、\(\mu=40,50\)の帰無仮説も棄却されないのを見てきましたね。
さらに、有意性水準は、「検定による判断が間違える確率」ではありません。正しい仮説とサンプルを何度も検定にかけたとき、棄却される割合のことです。
また、検定の結果で帰無仮説が棄却されたとしても、本当に帰無仮説が間違っているとは限らないことに注意しましょう。統計的検定には仮定があり、t検定ならば「データが正規分布に従っていて、ランダムサンプリングできている」というものがあります。結果のみに注目せず、仮定が満たされているかを考えるのは大事です。
しばしば、統計的仮説検定の結果は、試験薬に効果があったかどうかを判断するといった、意思決定(decision)に応用されます。
ここでも、仮説が採択される・棄却されることは、その仮説に意義がある・意義がないことを意味しないことに注意しましょう。
仮説検定やP値については多くの誤解があり、それについては次の動画がわかりやすいです。
以上、統計的仮説検定とは:平均の検定、t検定を例に、Juliaを使って紹介してきました。
検定を行うこと自体はそれほど難しくないので、実験しつつその意味を考えるのが大事だと思います。
木村すらいむ(@kimu3_slime)でした。ではでは。

Probability and Statistics: Pearson New International Edition
Pearson Education Limited (2013-07-30T00:00:01Z)
¥10,792 (中古品)

培風館 (1978-01-01T00:00:01Z)
¥5,280

Advanced Engineering Mathematics
John Wiley & Sons Inc (2011-05-03T00:00:01Z)
¥5,862 (中古品)